WARNING: This website is obsolete! Please follow this link to get to the new Albert@Home website!
Project server code update |
Message boards :
News :
Project server code update
Message board moderation
Previous · 1 . . . 3 · 4 · 5 · 6 · 7 · 8 · 9 . . . 17 · Next
| Author | Message |
|---|---|
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Ta. Looks like fpops estimate isn't too shabby then. But you need to exclude that contribution. In both the Seti cases, and in the CPU app case here that I've only looked at cursorily, the fpops_est have been what I would call 'reasonable'. I don't think it would be reasonable to ask of project developers to estimate more precisely than what theory tells them (though it's certainly open to debate) Overnight I've been musing on how to stage/phase/break-up the tests. Since there seems to be evidence of interaction between CPU & GPU scaling, I'd like to start with the coarse CPU scaling first, and prescribe watching all applications for effects when it's engaged. @Richard, yeah the pfc scale should be compensating handily for any initial SIMD related disagreement there (It's had enough time), but since the scaling swing is in the opposite direction to GPU, and likely below 1 as at seti (which implies magical CPU fairies), I believe the coarse scaling correction there should be the first step in isolation. Supporting effects include the SIMAP non-SIMD app on SIMD aware android client whetstone, as well as Seti's uniformly below 1 pfc_scales despite quite tight theoretically based estimates. The damping component I'll shift to pass 2. It's important, and has proven treatments available, but I feel that analysis of the impact of the unmitigated [CPU app] coarse scaling error is more important at this stage. [Edit:] i.e. in the examples given here, median credit awarded should be a bit over the prior fixed credit of 1000, rather than 500-600 , so the SIMD scaling correction of 1.5^2 = 2.25x seems appropriate given the numbers. For dominant single precision, That'd be 1.5 times for each step in logbase2 of the vector length, so 1.5x for mmx, 2.25x for SSE+, 3.35x for avx256 where the app and host support it), coarse correction will be just fine IMO, as damping will be added in pass 2. Maximum supported vector length in the app can be regarded as known, client scheduler requests contain the CPU features and OS, so a min() taken between the two. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
@Richard, yeah the pfc scale should be compensating handily for any initial SIMD related disagreement there (It's had enough time), but since the scaling swing is in the opposite direction to GPU, and likely below 1 as at seti (which implies magical CPU fairies), I believe the coarse scaling correction there should be the first step in isolation. Supporting effects include the SIMAP non-SIMD app on SIMD aware android client whetstone, as well as Seti's uniformly below 1 pfc_scales despite quite tight theoretically based estimates. Are you sure that the SETI rsc_fpops_est are 'tight'? I remember that when we were helping Josh Von Korff choose initial runtime estimates for Astropulse, we had a rule-of-thumb that the *stock* MB CPU app reached a DCF - only available scaling factor in those days - of ~0.2 on the then cutting-edge Intel Core2 range (Q6600 and similar). The stock SETI app has had internal despatch of at least some SIMD pathways for a long time, and more have been added over the years. Knowing Eric's approach to these matters - he's never wanted to exclude anyone from the search for ET, no matter how primitive their hardware - I suspect rsc_fpops_est may have been 'tight' for the mythical cobblestone reference machine (1 GHz FPU only), but never since. Certainly the same GPU I'm plotting here has a SETI APR of 180, again running two tasks at once. So, even allowing for the inefficient GPU processing of autocorrelations (which I don't think has been reversed into the AR-fpops curve), SETI thinks this card is twice as fast as the stock BOINC code here and at GPUGrid does. At GPUGrid, it runs pretty tight cuda60 code, and since the whole project has revolved around NV and cuda since they dropped the PS3 dead-end, I reckon they know their stuff. They over-pay credit, but that's a manual decision, not BOINC's fault. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Are you sure that the SETI rsc_fpops_est are 'tight'? Yes, to +/- 10% of actual operations w/o overhead (which is not 'paid' at this point). That's still quite a spread in user and machine utilisation terms, which is the entropy that damped responses should be absorbing (as opposed to estimates). That's still approximately 3.3-30x 'tighter' than the coarse scaling error induced by unnacounted for AVX multiplied by machine utilisation. Certainly the same GPU I'm plotting here has a SETI APR of 180, again running two tasks at once. So, even allowing for the inefficient GPU processing of autocorrelations (which I don't think has been reversed into the AR-fpops curve), SETI thinks this card is twice as fast as the stock BOINC code here and at GPUGrid does. At GPUGrid, it runs pretty tight cuda60 code, and since the whole project has revolved around NV and cuda since they dropped the PS3 dead-end, I reckon they know their stuff. They over-pay credit, but that's a manual decision, not BOINC's fault. It's relative. [You use the theoretically best serial algorithm for estimate, as opposed to reflect back implementation ineffeicient or otherwise]... On Seti the GPU autocorrelation uses my own 4NFFT method, so in [uncounted] computation it's 4x...Since that's drowned by latencies to the tune of 60% on high end cards, you roughly double the claim for that portion. Other areas (variable) are more efficient. Then divide the overall claim by about 3.3 times (because of AVX global pfc). The net result is 'shorties' that should be getting ~100 credits, getting ~40-60 A similar effect is happening here, with tasks that should be ~1000, seeing a median of ~500. It's not the project supplied estimates that are out, but the induced scaling error. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Are you sure that the SETI rsc_fpops_est are 'tight'? I have to say I'm ... surprised. For a recently completed task, I can see <rsc_fpops_est> 14979862651149.264000 <fpops_cumulative> 111064200000000.000000 Flopcounter: 38995606754768.391000 Because I'm running Anon. Plat., the first is scaled to allow the client to show a decent runtime estimate using it's internal reference speed. It seems to be using <flops> 9235454731.586426, although the APR on that machine is 122.47 GFLOPS. The second and third differ by Eric's imfamous 'credit multiplier' of x2.85, of course. I'll have to load up a machine with a stock app sometime and try that one again. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Are you sure that the SETI rsc_fpops_est are 'tight'? 'That' <rsc_fpops_est> has already been downscaled. 2.85x would indeed be a great compromise if on average most of the hosts were SSE+ (~2.25x) equipped with about a third taking up AVX (3.375x). On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
 Bernd Machenschalk Bernd MachenschalkVolunteer moderator Project administrator Project developer Send message Joined: 15 Oct 04 Posts: 1956 Credit: 6,218,130 RAC: 0 |
Attached a new host to Albert, looking through the logs i keep getting the following download error: Was related to the web code update. Shouldn't have affected crunching. Should be fixed now. BM |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
'That' <rsc_fpops_est> has already been downscaled. 2.85x would indeed be a great compromise if on average most of the hosts were SSE+ (~2.25x) equipped with about a third taking up AVX (3.375x). Yes, I said I was running anon. plat. I'll have to get a raw one on a stock machine. seeing a median of ~500 ?? My own machine - attached after the bulk of the averaging has been done by the population at large - is showing a median of 1716.32 currently. That's climbed from 1644.33 at last night's show. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
'That' <rsc_fpops_est> has already been downscaled. 2.85x would indeed be a great compromise if on average most of the hosts were SSE+ (~2.25x) equipped with about a third taking up AVX (3.375x). i.e. median on *my* GPU here early in the piece, which has been running one task at a time, from the figures you posted earlier at http://albert.phys.uwm.edu/forum_thread.php?id=9017&postid=112911 We know that after that it's been going up, It's not clear yet IMO whether that's a controlled rise/correction or another instability. [There's two scales fighting, the host app version driving it upward, and the global PFC scale selected from the underclaiming CPU app driving it down, which one wins is a matter of numbers] On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
i.e. median on *my* GPU here early in the piece, which has been running one task at a time, from the figures you posted earlier at http://albert.phys.uwm.edu/forum_thread.php?id=9017&postid=112911 Still rising inexorably here - this is roughly the last three days (right margin is midnight UTC tonight). Horizontal lines are 1K and 10K, still logarithmic. My minimum (of 60) is 1355 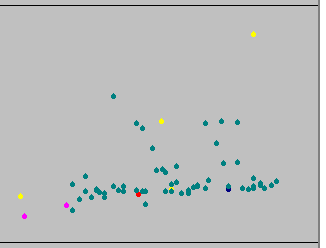 Edit - to your edit: there's no CPU app here - that was Eric's point. 'Binary Radio Pulsar Search' and 'Binary Radio Pulsar Search (Arecibo, GPU)' are deployed as different Applications on this project, not just different app_versions. |
|
Eyrie Send message Joined: 20 Feb 14 Posts: 47 Credit: 2,410 RAC: 0 |
Are you sure that the SETI rsc_fpops_est are 'tight'? CPU flops under anon are [unless supplied in app_info.xml] raw whetstone for CPU and some mystical figure for GPU. At some point it was just 10X CPU and I am seeing roughly 10x for Eve. rsc_fpops_est for anon is a combination of APR and rsc_fpops_est iirc. Queen of Aliasses, wielder of the SETI rolling pin, Mistress of the red shoes, Guardian of the orange tree, Slayer of very small dragons. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Still rising inexorably here - this is roughly the last three days (right margin is midnight UTC tonight). Horizontal lines are 1K and 10K, still logarithmic. My minimum (of 60) is 1355 No certainty in how that will react to correcting the CPU app scale as patch one. In an ideal world it wouldn't react at all (though I firmly believe it will react visibly, I'm open to surprises.). That's what I want to watch, because I suspect it should bump up a bit further, then level, drop and oscillate (for subsequent smoothing in patch two). Anyway, with such steady work it should have stabilised by now and hasn't so rolling up my sleeves for the first pass (CPU coarse scale correction) On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Eyrie Send message Joined: 20 Feb 14 Posts: 47 Credit: 2,410 RAC: 0 |
There is no underclaiming CPU app! edit: what Richard said... global pfc are for GPU apps only - but there are several of those according to applications Queen of Aliasses, wielder of the SETI rolling pin, Mistress of the red shoes, Guardian of the orange tree, Slayer of very small dragons. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
CPU flops under anon are [unless supplied in app_info.xml] raw whetstone for CPU and some mystical figure for GPU. At some point it was just 10X CPU and I am seeing roughly 10x for Eve. Yep, that's pretty much the way I remember it ( spaghetti, including assorted mysticism and voodoo :P). Once we get the cpu-misscalingout of the picture, pass 2 might either be focussed on smoothing/damping, GPU scale correction, or both. In any of those cases, I'll let what happens with CPU guide. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
... global pfc are for GPU apps only whatever the web pages call them (probably not the same thing), in code the global pfc_scale for a suite of applications is the lowest claiming application for given tasks (by unstable averages). That's then used to downscale the estimate of every other application wholesale, and is how the underclaiming SSE-AVX apps are dividing the credit. They are claiming fewer operations than it actually takes to do a task, evidenced by pfc_scales being below 1 ( magical fairy CPU applications doing work for free ) I'm telling you it takes no fewer than nlogn operations to do an FFT ... - AVX CPU + App tells me it did it in nlogn/3.3 . 'I'm Magic' - Server stupidly sets pfc_scale to 1/3.3 'This magic app wins' - Jason says 'hang on a minute, Boinc client uses broken inapplicable non-SIMD whetstone to calculate that... Ya canna defy the laws of physics, there are no CPU fairies or magic... It's using SIMD and doing up to 8 operations per cycle for an average of ~3.3x throughput' (scaling is about 50%) On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Eyrie Send message Joined: 20 Feb 14 Posts: 47 Credit: 2,410 RAC: 0 |
... global pfc are for GPU apps only that would be whatever _GPU_ application claims lowest! AVX doesn't come into play there. Don't ask me what happens when there is no CPU version to take the lead. well we see what happens we end up pretty low (compared to the dip CPU apps take as per my 'day zero' analysis. where did O put that? wiki?) take your pick of opencl_ati for win, mac linux and cuda versions for win mac and linux. Queen of Aliasses, wielder of the SETI rolling pin, Mistress of the red shoes, Guardian of the orange tree, Slayer of very small dragons. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
... global pfc are for GPU apps only I'm pretty sure the CPU apps will be claiming far fewer operations so be chosen as scale. Here is a bit special because of those aggregate GPU tasks, so how that's weaved in is another question ( i.e. treated as GPU Only? or 16x a CPU task ?). With the current logic pure GPU only projects would likely grant from 3.3x-100x the credit, and initial estimates not be all that bad. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
... global pfc are for GPU apps only Well, you're the one who's been walking the code, but let's standardise on one set of terminology. Using *BOINC* terminology, the hierarchy is Project
|__> Application
|__> App_version (each separate binary executable)The 'underclaiming SSE-AVX' *executables* are a suite within the BRP4 (CPU only) Application. That is different from, and will have a (if I understand you correctly) *different* pfc_scale from the suite of BRP4G (GPU only) According to the CreditNew whitepaper, normalisation is applied across versions of each application, not across the project as a whole. So, in the specific case at point (BRP4 and BRP4G), the GPU app will not be scaled by CPU concerns, because there isn't a CPU executable within the GPU suite. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
... global pfc are for GPU apps only That's where it depends on how they hooked in those *4G and *5G aggregates of 16 tasks. If the estimate is standalone, then there is no visible reason it should give us 3 second estimates for hour long tasks. If it is hooked in via a multiple of the CPU apps PFC_Scale &/or CPU app estimate, then that would explain it. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Eyrie Send message Joined: 20 Feb 14 Posts: 47 Credit: 2,410 RAC: 0 |
... global pfc are for GPU apps only JASON, CPU and GPU have different APPS here! there is a BRP app and a BRPG app. thta's like MB and AP on SETI... or are you saying pfc for MB and AP are the same? :P Queen of Aliasses, wielder of the SETI rolling pin, Mistress of the red shoes, Guardian of the orange tree, Slayer of very small dragons. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
JASON, CPU and GPU have different APPS here! No, and don't yell at me please ;) I am saying that the BRP4G and 5G estimates come from CPU app estimates multiplied by 16 ---> different app & hardware, but estimates are linked. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
This material is based upon work supported by the National Science Foundation (NSF) under Grant PHY-0555655 and by the Max Planck Gesellschaft (MPG). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the investigators and do not necessarily reflect the views of the NSF or the MPG.
Copyright © 2024 Bruce Allen for the LIGO Scientific Collaboration