WARNING: This website is obsolete! Please follow this link to get to the new Albert@Home website!
Posts by Richard Haselgrove |
|
1)
Message boards :
Problems and Bug Reports :
Intel GPU tasks error out
(Message 113278)
Posted 27 Jul 2014 by Richard Haselgrove Post: It worked. Thanks! Look at the application details page for each of your hosts - e.g. https://albert.phys.uwm.edu/host_app_versions.php?hostid=8551 for the lowest numbered. When the 'Number of tasks completed' for the Gamma-ray pulsar search #3 application reaches 11, that host will be safe to leave to its own devices. But don't remove the app_config.xml file from any of them until you're able to set the utilisation factor in preferences back to 1.0, or all hell will break loose! Note that 'completed' requires that the tasks be validated, not just returned successfully. I see that you've been paired with that dreadful batch of 40-odd intel-gpu hosts with bad OpenCL 1.1 drivers (ID numbers in the low 9xxx range) - that will delay your completions until well-managed hosts come along to sort out the inconclusive validations. |
|
2)
Message boards :
Problems and Bug Reports :
Intel GPU tasks error out
(Message 113275)
Posted 26 Jul 2014 by Richard Haselgrove Post: Ah, the imfamous Exit status 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED You could try the workround I suggested in the thread of that name, at message 113253. Use the name einsteinbinary_BRP4 in your app_config.xml file. No, scrub that - it's a hsgamma_FGRP3 task, same as the example: I hadn't realised we had FGRP for intel_gpu. Afterthought - not sure if the FGRP utilisation factor control on the preferences page is applied to intel_gpu apps - you'll have to experiment and find out for yourself. If the workround doesn't work, you'll have to do it the old-fashioned way - increasing <rsc_fpops_bound> in client_state.xml by a factor of 100 or so for each task. |
|
3)
Message boards :
News :
Project server code update
(Message 113271)
Posted 23 Jul 2014 by Richard Haselgrove Post: Time for another inflation update. 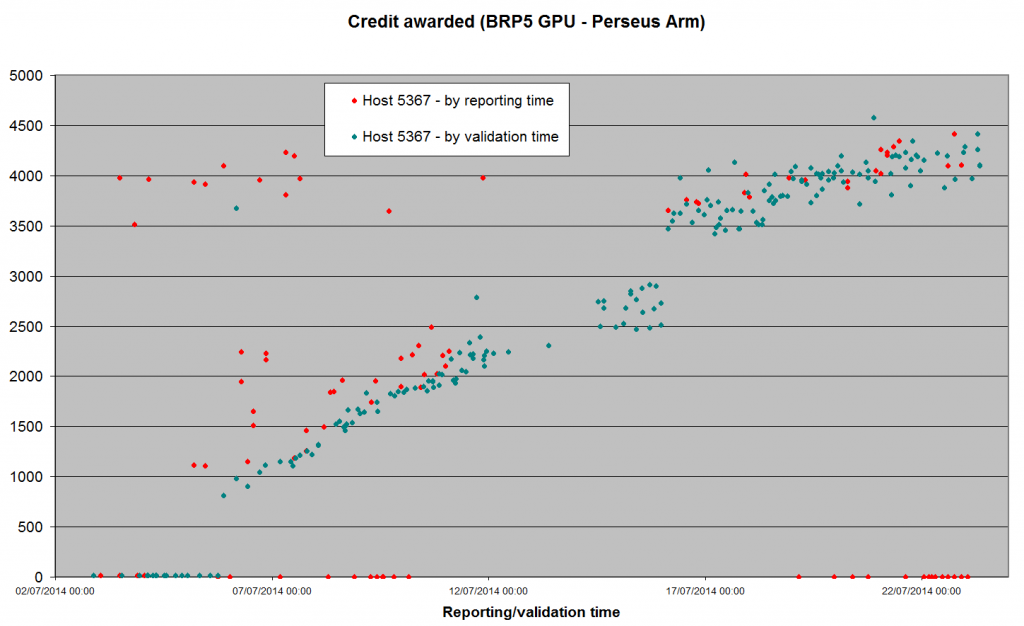 There's a very clear discontinuity at midnight on 16 July - which is exactly when the second app_version (opencl-ati for Windows/64) reached a pfc_n of 101. Unfortunately, we don't have a third app on the cards for a while yet - cuda32-nv270 for Linux has been stuck at 75 for two days now. Because I can only contribute NV for Windows (946 and counting), I've switched back to BRP4G Arecibo GPU, to check that nothing untoward has been happening while I've been concentrating on Perseus (it hasn't). So, here's a question to ponder on, while we go into the Drupal migration next week, and then possibly some new apps to test: Why has CreditNew picked something ~4,000 credits to stabilise on for Perseus tasks, and something ~2,000 credits for Arecibo tasks? That's a ratio of - in very rough trend terms - 2::1, when the runtimes are closer to 3::1 - close and steady in my own case, and similar on all the other hosts I've spot-checked (including other OSs and GPU platforms). Is this perhaps more evidence that the ultimate credit rates area very largely determined by <rsc_fpops_est>, where there are no complications from CPU apps to contend with? The figures for the two apps I'm comparing here are: Arecibo <rsc_fpops_est> 280,000,000,000,000 Perseus <rsc_fpops_est> 450,000,000,000,000 ratio 1.6::1 |
|
4)
Message boards :
News :
Project server code update
(Message 113267)
Posted 16 Jul 2014 by Richard Haselgrove Post: Looks like the next bout of inflation has set in on the Perseus Arm - I think we're above Bernd's parity value now. 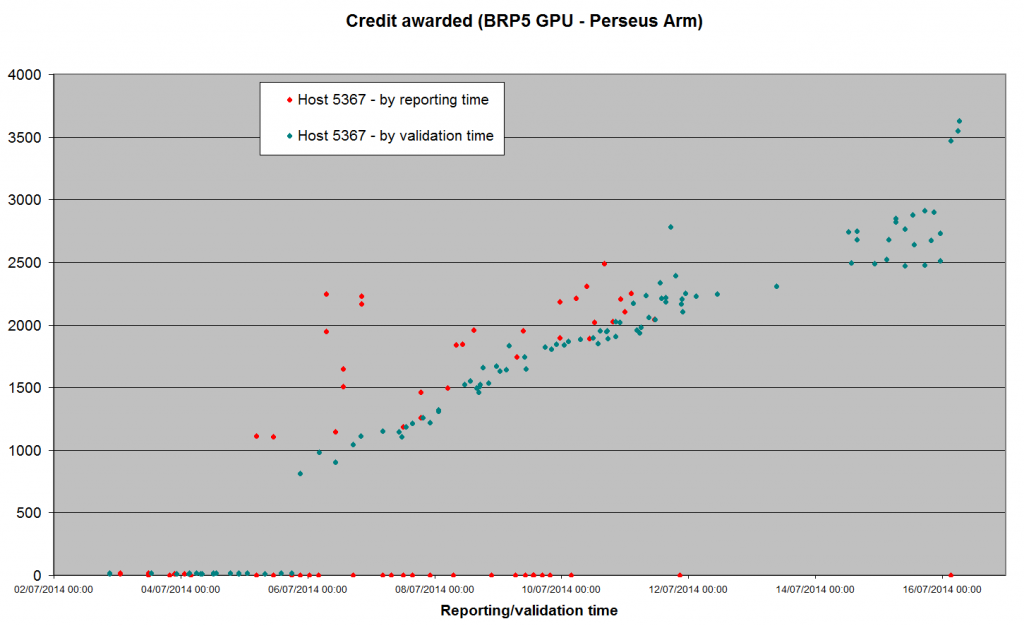 Meanwhile, the Gamma search - after a brief flirtation with the ~2,000 level - has dropped back down to the the low hundreds. May be correlated with a scaling adjustment when a second app_version (Win64/intel_gpu) reached the 100 threshhold around 16:00 UTC Tuesday. Edit - or it might have been CPU normalisation kicking in. We have Win32/SSE above threshhold now as well, and Win32/plain will reach it any time now (99 valid at 08:00 UTC) |
|
5)
Message boards :
Problems and Bug Reports :
Big credit difference FGRPPSSE #3 ver1.12
(Message 113265)
Posted 15 Jul 2014 by Richard Haselgrove Post: It'a an observed part of the problems with the standard BOINC 'CreditNew' programming. This beta test project - Don't expect ANYTHING to work here - as it says on the front page - is deliberately allowing the standard code to run for a while, so that we can see just how broken it is, and what needs fixing. Please refer to the news thread Project server code update for further details. |
|
6)
Message boards :
News :
Project server code update
(Message 113260)
Posted 13 Jul 2014 by Richard Haselgrove Post: Been a while since we had a statistical report on the new server code. 1) The Arecibo GPU apps seem to have settled down. Just a few validations trickling in from the hosts I've been monitoring, and all (except Claggy's laptop) seem to be +/- 2,000 credits - about double what Bernd thought the tasks were worth before we started. Jason Holmis Claggy Juan Juan Juan RH Host: 11363 2267 9008 10352 10512 10351 5367 GTX 780 GTX 660 GT 650M GTX 690 GTX 690 GTX 780 GTX 670 Credit for BRP4G, GPU Maximum 2708.58 2313.45 10952.0 7209.47 6889.8 6652.9 4137.85 Minimum 115.82 88.84 153.90 1667.23 1244.41 1546.02 1355.49 Average 1408.03 1549.45 3256.04 2472.29 2026.98 2205.24 1980.88 Median 1586.65 1831.19 2244.85 2123.89 1910.04 1997.84 1916.41 Std Dev 626.98 633.96 2258.33 948.11 592.78 637.63 267.22 nSamples 87 171 116 161 151 189 670 I've also plotted the same hosts' results for BRP5 (Perseus Arm). The logarithmic plot looks similar to the lower half of the 'trumpet' graph that emerged from Arecibo. Remember that we saw ridiculously low numbers to start with: we still haven't reached Bernd's previous assessment of value. 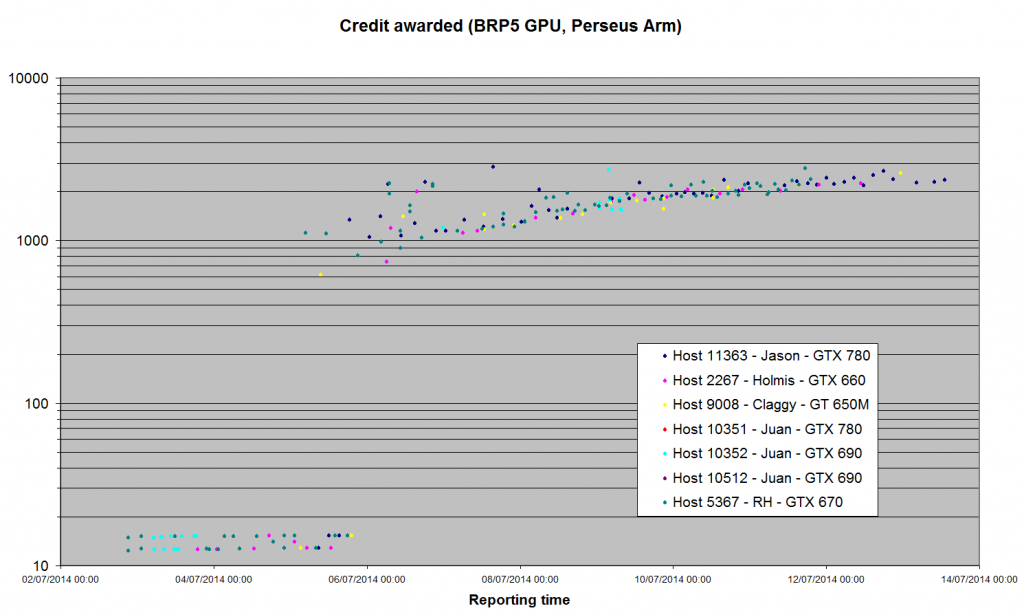 The linear graph shows more clearly that we haven't reached a steady state yet: I'll switch my GTX 670 back to this application once we have our 100 validations for its version of the Gamma search (which should happen this evening). 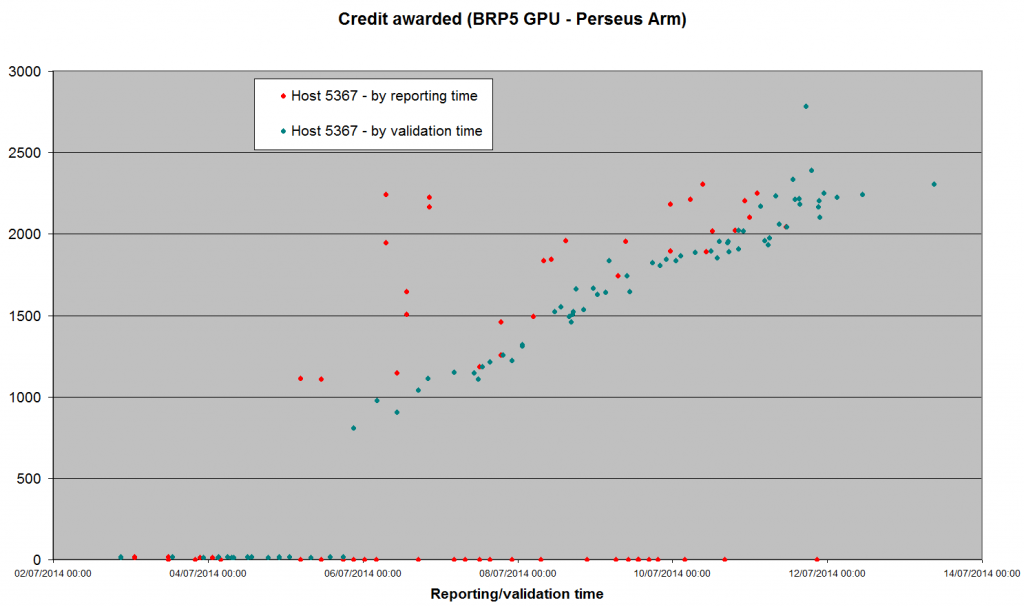
|
|
7)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113257)
Posted 11 Jul 2014 by Richard Haselgrove Post: Well, we're making progress with the validations. As at 22:00 UTC (Bernd has kindly given us some access to the statistics), we had the following validations, all from Windows/64. plan_class n FGRPopencl-ati 9 FGRPopencl-intel_gpu 5 FGRPopencl-nvidia 20 I'm still not sure what will happen when that last line reaches 100, but it looks like I won't have to keep watching overnight. |
|
8)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113253)
Posted 11 Jul 2014 by Richard Haselgrove Post: OK, guys, gals, and fellow alpha-testers. Again, speaking specifically about FGRP (Gamma-ray pulsar search #3) GPU apps only: I've got a workround for the -197 EXIT_TIME_LIMIT_EXCEEDED. First, set up an app_config.xml file containing this section: <app_config>
<app>
<name>hsgamma_FGRP3</name>
<max_concurrent>1</max_concurrent>
<gpu_versions>
<gpu_usage>1</gpu_usage>
<cpu_usage>1</cpu_usage>
</gpu_versions>
</app>
</app_config>Make BOINC read the file, and check that it's been found properly: this is important, else the next stage will try to make your computer run 10 tasks at once.... Second, check that you understand the host/venue mapping for your fleet, and identify which host(s) and venue(s) will be running the FGRP3/GPU tests. Go to the Albert@Home preferences page for your account, and for the venue(s) you've selected for the test, set the "GPU utilization factor of FGRP apps" low. Really low. Crazy low, like 0.1 This is madness (don't say you haven't been warned), but with app_config.xml keeping the lid on your machine, it works. Third, allow and fetch new FGRP3/GPU work for the machine. You should see the estimated run time for any work already cached on the machine jump five-fold - that's your confirmation that the setting has been transferred properly. That should get us through to the first 100 validations for the project as a whole. Watch out for further advice on how we might handle phase 2. |
|
9)
Message boards :
News :
Project server code update
(Message 113252)
Posted 11 Jul 2014 by Richard Haselgrove Post: Please cross-refer to thread 'Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED' in the 'Problems and bug reports' area before carrying out the tests that Eyrie requested. |
|
10)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113251)
Posted 11 Jul 2014 by Richard Haselgrove Post: Unfortunately, I think Eyrie has jumped the gun on this one. Speaking specifically about FGRP (Gamma-ray pulsar search #3) only: My NVidia 420M laptop (host 11359) has just been allocated new work from the v1.12 run. It was sent out with the 'conservative' (first stage onramp) speed estimate of 27.76 GFlops: that's very close to the 23.59 GFlops the same host achieves on BRP4G-cuda32-nv301. BUT: FGRP is a beta app, which makes very little use of the GPU as yet. It runs much, much slower than BRP4G-cuda32-nv301 on my hardware. The tasks would have got error 197 if I hadn't taken precautions. I can't say whether the problem is Einstein's programming, or NVidia's OpenCL implementation, but at this initial stage for the new app_version, we can't blame BOINC. But we're back to square one with the validation count. Could testers please run more of these tasks (with edited <rsc_fpops_bound>, so they can complete), please? We still need to test how BOINC handles the transitions at 100 validations for the app_version across the project as a whole, and 11 validations for each individual host. |
|
11)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113242)
Posted 6 Jul 2014 by Richard Haselgrove Post: I have not resumed testing on this issue, and do not anticipate doing so. I replaced my GTS 240 with a second GTX 660 Ti, and am focusing on GPUGrid and Poem. Exactly. Specifically during what we are calling "stage 2 of the onramp", between 100 global validations for the project as a whole, and 11 local validations for the individual host - the phase during which flops determined by "PFC avg" can be seen in the server logs. If you're not testing any more, and we understand that much, why do you wish to prevent us discussing other matters of mutual interest in this thread? |
|
12)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113240)
Posted 6 Jul 2014 by Richard Haselgrove Post: Let's keep this thread on the topic of its subject, please. Your last contribution to the subject, five days ago was. Just wanted to post to mention that I will likely no-longer be testing these problematic work units. Have you come back to testing, and if so, what have you discovered in the meantime about the cause of the problems? |
|
13)
Message boards :
News :
Project server code update
(Message 113235)
Posted 6 Jul 2014 by Richard Haselgrove Post: WU 618702 looks perkier - v1.39/v1.40 cross-validation. |
|
14)
Message boards :
News :
Project server code update
(Message 113233)
Posted 5 Jul 2014 by Richard Haselgrove Post: The server seems to have accepted that the 'conservative' values for BRP5 v1.40 were correct after all: [AV#934] (BRP5-cuda32-nv301) adjusting projected flops based on PFC avg: 19.76G According to WU 619924, the figures for v1.39 were rather different. |
|
15)
Message boards :
Problems and Bug Reports :
Errors - 197 (0xc5) EXIT_TIME_LIMIT_EXCEEDED
(Message 113232)
Posted 5 Jul 2014 by Richard Haselgrove Post: I've already reported to Bernd, by email: And, (4), a quite different gripe. https://albert.phys.uwm.edu/results.php?hostid=11362 is plodding through some FGRP #3 OpenCL tasks. EVERY SINGLE ONE (sorry for shouting) has been paired with a different one from a sequence of apparently identical, anonymous, "Intel(R) Core(TM) i3-3220 CPU" with HD 2500 iGPUs. So far, I've returned results paired with hosts: He replied, I'll take a look; not sure this will fit in today, though. 'today' being Thursday 03 July. |
|
16)
Message boards :
News :
Project server code update
(Message 113229)
Posted 4 Jul 2014 by Richard Haselgrove Post: Thanks, yes thas easely explain the crunching time diferences. Seems like i missunderstood something again. I have the ideia we where asked for the test period to run 1 WU at a time to avoid any noise from one task transfered to the other. Sorry about that. We've all been pretty much making it up as we go along. I think I made that choice some time before somebody else posted the "one at a time" suggestion: I decided it was better to keep "steady as she goes" - there would be more noise in the results if you keep changing the utilisation factor. Most of the time while running Arecibo tasks I got an incredibly stable run time: that counts for more in extended tests, where it's the measured APR that counts, and little (if any) weight is given to the theoretical "peak GFLOPS" the card is capable of. |
|
17)
Message boards :
News :
Project server code update
(Message 113227)
Posted 4 Jul 2014 by Richard Haselgrove Post: Richard That seems simple - I'm running two at a time, so effective throughput would be one task every 6k seconds (on your figures - I haven't looked at the data for BRP5 in any detail yet). The efficiency gain from running two together is probably more significant than the i5/i7 difference. |
|
18)
Message boards :
News :
Project server code update
(Message 113225)
Posted 3 Jul 2014 by Richard Haselgrove Post: Most of the BRP5 'Perseus Arm' tasks I've seen so far have old WUs which have been lying around in the database for some time, with multiple failures - not sure whether anybody has looked to see if that affects the credit granting process - even if only by the averages shifting between initial creation and final validation (I don't think so, because I don't think anything about the prevailing averages are stored into the task record when it's created from the WU - but I haven't looked at the database schema or the code). But I've just validated the first 'clean', two replications only case: WU 625789 For 12.62 credits. |
|
19)
Message boards :
News :
Project server code update
(Message 113217)
Posted 2 Jul 2014 by Richard Haselgrove Post: Well, here's the first conundrum: All Binary Radio Pulsar Search (Perseus Arm Survey) tasks for computer 5367 After 200 minutes of solid GTX 670 work on Perseus, I earn the princely sum of ... 15 credits! |
|
20)
Message boards :
News :
Project server code update
(Message 113214)
Posted 2 Jul 2014 by Richard Haselgrove Post: Nothing's been changed yet... I got something similar - 25.25Gflops and 4h57m02s24 2014-07-02 17:43:24.7141 [PID=19995] [version] [AV#934] (BRP5-cuda32-nv301) using conservative projected flops: 25.25G But note that line I've picked out: that means there are fewer than 100 completed tasks for this app_version yet, across the project as a whole. The worry is that when 100 tasks have been completed, but before you have completed 11 tasks on your host (to use APR), you'll see adjusting projected flops based on PFC avg and some absurdly large number. That'll be when the errors (if any) start. |
Next 20
This material is based upon work supported by the National Science Foundation (NSF) under Grant PHY-0555655 and by the Max Planck Gesellschaft (MPG). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the investigators and do not necessarily reflect the views of the NSF or the MPG.
Copyright © 2024 Bruce Allen for the LIGO Scientific Collaboration