WARNING: This website is obsolete! Please follow this link to get to the new Albert@Home website!
Project server code update |
Message boards :
News :
Project server code update
Message board moderation
Previous · 1 . . . 14 · 15 · 16 · 17
| Author | Message |
|---|---|
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Been a while since we had a statistical report on the new server code. 1) The Arecibo GPU apps seem to have settled down. Just a few validations trickling in from the hosts I've been monitoring, and all (except Claggy's laptop) seem to be +/- 2,000 credits - about double what Bernd thought the tasks were worth before we started. Jason Holmis Claggy Juan Juan Juan RH Host: 11363 2267 9008 10352 10512 10351 5367 GTX 780 GTX 660 GT 650M GTX 690 GTX 690 GTX 780 GTX 670 Credit for BRP4G, GPU Maximum 2708.58 2313.45 10952.0 7209.47 6889.8 6652.9 4137.85 Minimum 115.82 88.84 153.90 1667.23 1244.41 1546.02 1355.49 Average 1408.03 1549.45 3256.04 2472.29 2026.98 2205.24 1980.88 Median 1586.65 1831.19 2244.85 2123.89 1910.04 1997.84 1916.41 Std Dev 626.98 633.96 2258.33 948.11 592.78 637.63 267.22 nSamples 87 171 116 161 151 189 670 I've also plotted the same hosts' results for BRP5 (Perseus Arm). The logarithmic plot looks similar to the lower half of the 'trumpet' graph that emerged from Arecibo. Remember that we saw ridiculously low numbers to start with: we still haven't reached Bernd's previous assessment of value. 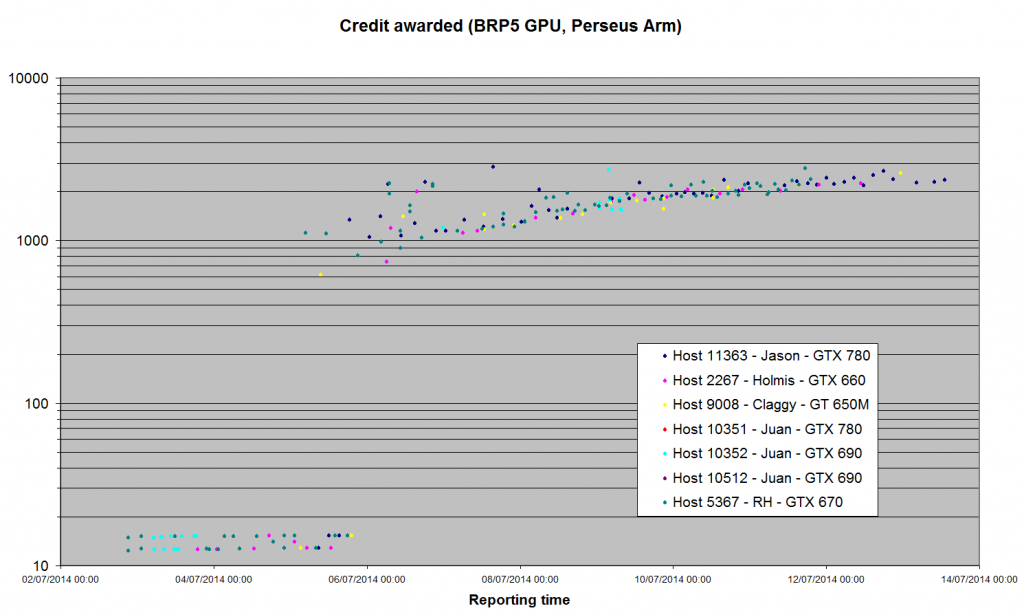 The linear graph shows more clearly that we haven't reached a steady state yet: I'll switch my GTX 670 back to this application once we have our 100 validations for its version of the Gamma search (which should happen this evening). 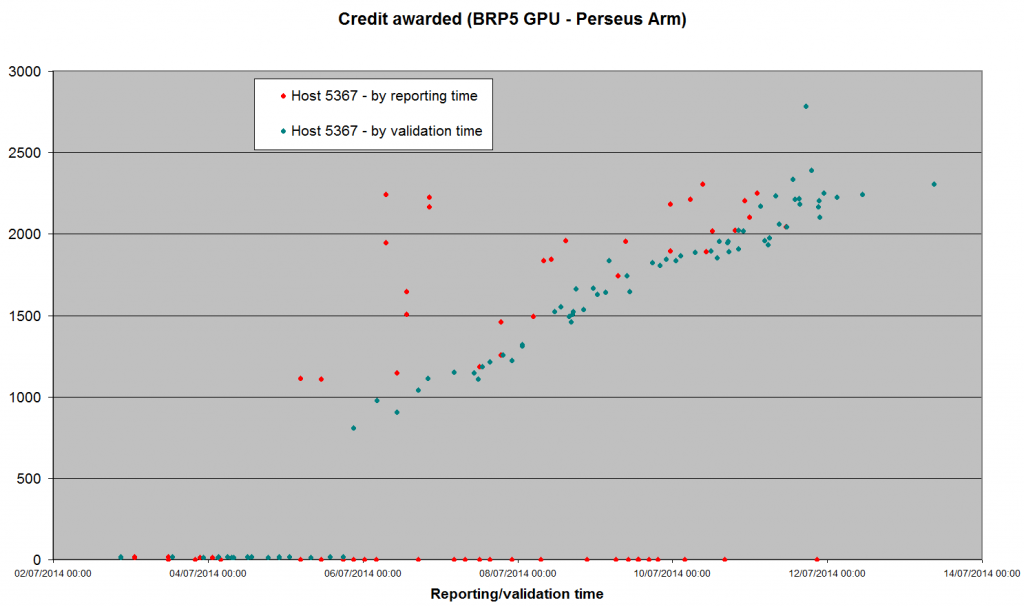 |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
1) The Arecibo GPU apps seem to have settled down. Just a few validations trickling in from the hosts I've been monitoring, and all (except Claggy's laptop) seem to be +/- 2,000 credits - about double what Bernd thought the tasks were worth before we started. Having quite a bit more understanding of the nature of the beast now, the major challenges making predictions with the current mechanism implementation are twofold. First, in the GPU only sense, we see a discrepancy between the chosen normalisation (for credit purposes) efficiency point of 10%, and the 'actual' efficiency of somewhere in the region of ~5% for single task per GPU operation. This amounts to an effective increase of the former application's award. Second, and a little more insidious, understanding the limitations of average based numerical control with respect to noisy populations, quickly reveals that uncertainty in any specific numbers, as partly reflected in the standard deviations, guarantees many of the numbers intended for comparison of hosts, applications, credits, and cheat detection/prevention, are arbitrary relative to the user and project expectations for the usefulness & meaning of those numbers. Tools (algorithms etc) exist to improve these situations, namely those of making useful estimations, handling various kinds of 'noise' such as host change, real measurement error and an unlimited range of usage variation conditions, to or beyond end-user expectation. Refining these mechanisms, using such design tools, ultimately will reduce the development and maintenance overhead constantly dogging the Boinc codebase, while simultaneously making the system more resilient/adaptive to future change. There is also the angle that high quality available numbers can potentially be more useful in global scientific contexts, than just for Credit/RAC & individual needs, having applications in fields such as distributed computing, computer sciences, and engineering fields, probably among more. @All: In those lights, I'd like to thank everyone here for helping out. I'm progressing to a detailed simulation and design phase, that will take some time to get right. Please keep collecting, observing, commenting etc, and we're on the right road. Jason On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Looks like the next bout of inflation has set in on the Perseus Arm - I think we're above Bernd's parity value now. 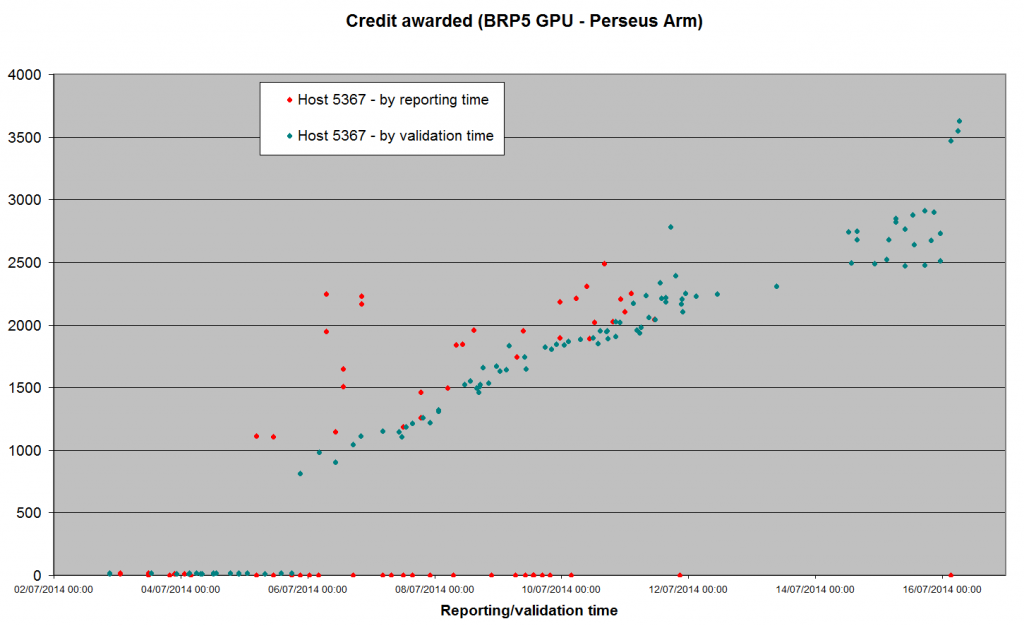 Meanwhile, the Gamma search - after a brief flirtation with the ~2,000 level - has dropped back down to the the low hundreds. May be correlated with a scaling adjustment when a second app_version (Win64/intel_gpu) reached the 100 threshhold around 16:00 UTC Tuesday. Edit - or it might have been CPU normalisation kicking in. We have Win32/SSE above threshhold now as well, and Win32/plain will reach it any time now (99 valid at 08:00 UTC) |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Edit - or it might have been CPU normalisation kicking in. We have Win32/SSE above threshhold now as well, and Win32/plain will reach it any time now (99 valid at 08:00 UTC) With last server data dated 16th, looks like a bit of an interesting illustration going on there. Lowest pfc average, with n > 100, is indeed FGRPSSE with a value of ~10.6. Opencl nv seems to be ~144. Now nv-OpenCL's is expected to be about 2x what it should be due to the mechanism normalising to 10% efficiency instead of the more realistic 5%... so picture the nv one as 'corrected' ~144/2 -> 72 (rough is good enough here) CPU SSE has an approximate underclaim of 1.5^2 = 2.25x , so we take 10.6*2.25-> 23.85 'corrected' for the CPU case (again rough is better than uncorrected inputs) So now we know the relative efficiencies of the implementations, a much tighter ~3x spread than the original uncorrected (noisy) numbers suggest. Right now credit is awarded based on the minimum pfc app, so about a third of what the GPU one would be 'asking'. Intuitive eyeballs say the GPU population is going to be larger, by sheer throughput. The 'right' credit is in between the corrected CPU and GPU figures, weighted a fair bit to the GPU case. There's tools for determining that too, better than averages. Net effect of the simplified/corrected/improper-assumption-removed mechanism would be an even higher quality (more trustworthy) number in between the CPU & GPU case, with a weighting bonus encouraging optimisation, and inherently rejecting likely fraudulent claims (another possible source of noise disturbances). So likely in the region of ~2x what win CPU SSE only validations would award now. I'm surprised how well that correlates with the seti@home astropulse case, and it points the bone directly at the seti@home multibeam case for AVX enabled app underclaims with no peak flops correction. Wow, we nailed this to the wall good and proper. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Time for another inflation update. 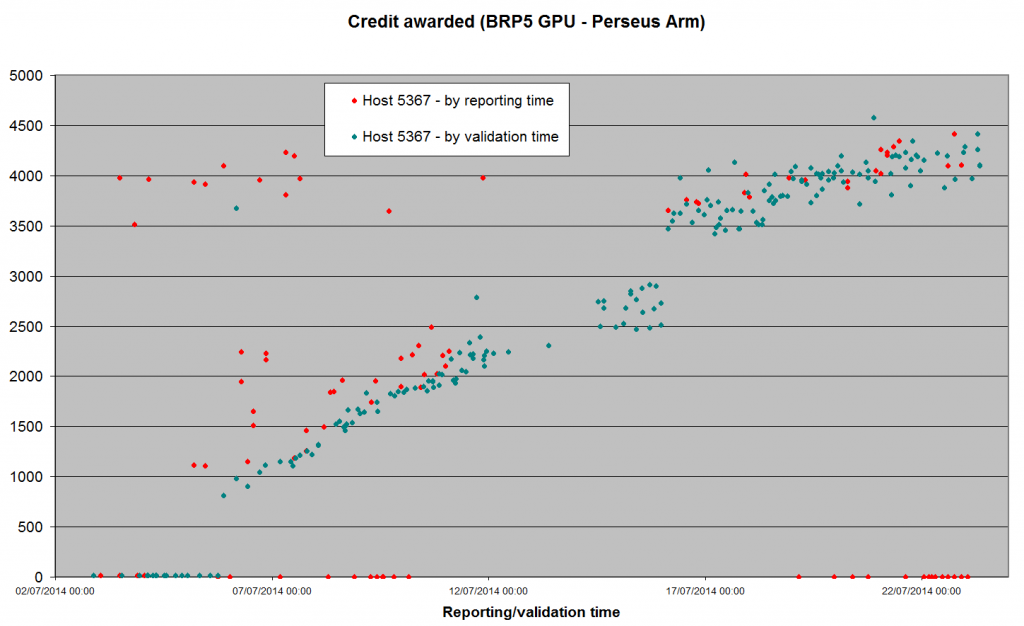 There's a very clear discontinuity at midnight on 16 July - which is exactly when the second app_version (opencl-ati for Windows/64) reached a pfc_n of 101. Unfortunately, we don't have a third app on the cards for a while yet - cuda32-nv270 for Linux has been stuck at 75 for two days now. Because I can only contribute NV for Windows (946 and counting), I've switched back to BRP4G Arecibo GPU, to check that nothing untoward has been happening while I've been concentrating on Perseus (it hasn't). So, here's a question to ponder on, while we go into the Drupal migration next week, and then possibly some new apps to test: Why has CreditNew picked something ~4,000 credits to stabilise on for Perseus tasks, and something ~2,000 credits for Arecibo tasks? That's a ratio of - in very rough trend terms - 2::1, when the runtimes are closer to 3::1 - close and steady in my own case, and similar on all the other hosts I've spot-checked (including other OSs and GPU platforms). Is this perhaps more evidence that the ultimate credit rates area very largely determined by <rsc_fpops_est>, where there are no complications from CPU apps to contend with? The figures for the two apps I'm comparing here are: Arecibo <rsc_fpops_est> 280,000,000,000,000 Perseus <rsc_fpops_est> 450,000,000,000,000 ratio 1.6::1 |
 zombie67 [MM] zombie67 [MM] Send message Joined: 10 Oct 06 Posts: 130 Credit: 30,924,459 RAC: 0 |
Just FYI, I had to take my two CUDA machines off albert for a while. I need to help a team mate at another project. I will be back. This thread is too big to read through it all. I am back with my two GPUs. Is that still relevant? Or can I mess with my settings as I see fit? Dublin, California Team: SETI.USA  |
|
Claggy Send message Joined: 29 Dec 06 Posts: 78 Credit: 4,040,969 RAC: 0 |
My Ubuntu C2D T8100 Laptop has been crunching both Astrouplse_v7 and Gamma-ray pulsar search #3 v1.12 and (FGRPSSE) tasks at the same time, the Astropulse tasks from the four app_versions initially were each estimated at sometime like one hundred and fifty hours, once their 100 validations were in, their estimates dropped to a value below reality, All tasks for computer 68093 Application details for host 68093 With Gamma-ray pulsar search #3 v1.12 and (FGRPSSE) the same has happened, the task durations are also under estimated, meaning Boinc over fetches, and can't complete the tasks in time, (I think it under estimated from the start through), now it's validations have passed 11, Boinc has a better gasp on how long these tasks take and hasn't fetched so many, and is slowly catching up again, It's cache setting is set to about one day to one and a half days (It's remote from me at the moment) All tasks for computer 10230 Application details for host 10230 Shouldn't the post 100 validation overall and pre 11 host app validation still be a bit conservative, and not cause over fetch? Claggy |
This material is based upon work supported by the National Science Foundation (NSF) under Grant PHY-0555655 and by the Max Planck Gesellschaft (MPG). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the investigators and do not necessarily reflect the views of the NSF or the MPG.
Copyright © 2024 Bruce Allen for the LIGO Scientific Collaboration