WARNING: This website is obsolete! Please follow this link to get to the new Albert@Home website!
Project server code update |
Message boards :
News :
Project server code update
Message board moderation
Previous · 1 . . . 9 · 10 · 11 · 12 · 13 · 14 · 15 . . . 17 · Next
| Author | Message |
|---|---|
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Probably time for a stats show, then. Hah! good idea, and there's the rub. Without damping those averages, won't happen. I felt the need for number reset to observe what any new application would do when installed, point being that number of platforms coming on line is accelerating. Your own (SD ~20 seconds -> variance 400 seconds -> 10%), then the same with your identical wingman. When averaging Murphy says he'll be 10% high and you'll be 10% low, so now it's 20%. Then both your host scales factor in some percentage you use your hosts for anything, and background tasks. That's a natural world input unfiltered/unconditioned (which is a no-no). On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
sample size is a bit low for good statistics but with THAT graph you can;t expect a reasonable SD. Yeah, David's using 10 validations and 100 for his average sample sets, host and app-version scales. That's why the nyquist limit kicks in to create artefacts when scales are adjusted with each validation. The frequency of change is higher that the nyquist limit. Ideal would be continuous damped averages (controller), Still musing whether to that as separate pass 2, or combine it with the CPU coarse scale correction. Probably easier to monitor/analyse the effects if separate, so I'll keep going on those lines. Off for a break, then back to more documentation for the patch passes. Hopefully skeletons will be ready for inspection soon. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
 nenym nenymSend message Joined: 13 Jun 11 Posts: 14 Credit: 10,001,988 RAC: 0 |
Notices from ordinary cruncher. Some observations I haven't seen be mentioned here (maybe my bad observations or trivial for you - experts): - Run time of Intel_GPU apps depends on type of CPU apps crunched by CPU, especially AVX/FMA3 application has strong effect (PG LLR/AVX&AVX2&FMA3, Asteroids AVX on Haswell, Beal and MindModeling SSE2 too), - CPU time of CPU apps depends on type of Intel_GPU app concurrently running, e.g. Collatz mini has nearly no effect, on the other side Einstein BRP and Seti AP apps can double the CPU time, - Run time of CUDA apps depends on type of Intel_GPU app concurrently running (not sure if CUDAOpenCL and ATIOpenCL too) - GPU load of CUDA is the same, - Run time of some types GPU apps can be strongly shortened by manipulation with CPU process priority (if priority of BRP process set to Realtime, Run time is half-length on Intel_GPU). A bit OT, but......it's my point of view: What can I see for the time being: - a hard work and analysis  , ,- David's RNG seems to be a fixed credit compared to the granted credit here for GPU apps. No offense, but are you sure by chance to catch up that chaotic system, as a Boinc space is? It is really a great deal. I see as a simplest way the fixed credit scheme for tasks of application, which length vary -+ 15 % on "standard" machine. Your work is hard and great, but what is the goal? If "fair" credit scheme for tasks of application using different app_ver, platform and plan_class (SSEx, AVXx, FMA3, GPU Intel, CUDA, OpenCL) with big vary of length....what is the fair credit? For the same reference WU the same credit independently on crunching machine (close to a fixed credit scheme), or credit depended on a "benchmark" (i.e. vary credit for the same reference WU), which is nonsense in the world of AVX/FMA3 and GPU hosts? What I see is effort to reach the benchmark asymptote. In despite of my point of view my machines stay here and helps to find the way. It is very interesting for me to look over your work and analysis as my job are chaotic systems, too. (to be clear partially predictable by Poisson/Binomic distribution, i.e. "without memory") |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Thanks nenym, Yes some of the objectives will not be as clear here straight away, mostly because of the cosistency of the tasks, and until now it's been fixed credit. It's those same features here that make it a great sandbox to put the system under the microscope. More detailed objectives & experimental procedure are being drafted, but very short overview is this: Time estimates and credit as estimate of 'work': - On projects with multiple application, like at Seti, there exists a mismatch between applications which can lead to hoarding and mass aborting in some cases to juggle work & cherry-pick. The intent written into the system basically says that should not happen as much as it does (about 2x discepancy) - +/- 30%+ makes RAC or credit pretty useless (IMO and some others) for its purpose (to users) of comparing host to host, hardware to hardware, application to application etc - The randomness can and does upset bringing new hosts online, in particular when estimates start really bad, such as when here starts and the GPUs hit time exceeded errors. That's bad juju for retaining new users, and possibly for application development - It also appears that the current system penalises optimisation. So yes, on one hand it's easy to regard the credit system as academic and not critical for the science, but on the other it becomes critical for time estimation, which is key to scheduling from server side right through to the client. That covers why I feel it has to be addressed. As for why have a scaling credit system at all ? In another direction, fixed estimates and credit make work for project developers (often with little funding) every time there is a major new application or platform. Something that will dial in automatically saves effort and money in the long run (like cruise-control) For can such a chaotic system be corrected ? Yes, if you use control theory. Here is an example from CPU 'shorties' on a host from Seti-beta. Those tasks are all the same length so should really get similar credit etc. The smoother curve is one that used a simple 'PID controller' to replace the credit calculation. it was started deliberately off target so as to see how it settled. Note also that the CPU credit system there has a scale error, so for easy comparison the new smooth & correct line is divided by 3. (it would be up over 90 credits if not scaled down)  Here is the not scaled down version:  and here is a picture of a PID controller in mechanical form:  On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
nenym Send message Joined: 13 Jun 11 Posts: 14 Credit: 10,001,988 RAC: 0 |
Thanks jason_gee for explanation. I agree with you, a fixed credit scheme (and a "measured work done scheme" - rosetta, AQUA, Seti MB years ago) means a lot of complications for developers, on the other side is popular independently on target RAC. Notes (theory): Maybe D part of regulation (feedback) is too strong or R part too weak because I see the same waves as on a oscilloscope measuring of not well designed regulation with tendencies to vibration (for some frequencies) missing the asymptote. In that case I part has to chance to win. Good test for stability is repeated Dirac impulse, theory e.g. here. I know that CreditNew works very well for some projects (WEP M+2, Seti AP ...), but these has units with close run times. On the other side on projects having very different times it seems to be RNG (LHC vary 1:3 for my i5-4570S). Run time/ CPU time/ Credit 20,679.88/ 20,046.41/ 291.51 WU 346.51/ 336.59/ 1.84 WU Notes (how to bestir/cheat the CreditNew): a) in stable state (CPU time ~ Run time) start high CPU load by third application (e.g. GPU crunching, Autocad 3D rendering...), credit per CPU time rises b) to make a notepad overclocking = false benchmark. It works for cca 10 tasks, then credit normalises. If tasks are long enough, cheated credit is noticeable. After 10 tasks it is necessary to crunch other project and to return back after time for 100 tasks, in that case the system "forgets". Cherry-picking: where do you see source causation for it, on the project's side or on the cruncher's side? Current system penalises optimisation: it's what I really hate on CreditNew (and benchmark CreditOld too). I lived in "socialist" country for 34 years and be sure we don't have the same stomachs. If I work hard and lot (optimised AVX/FMA3 apps) I eat more and must visit fitness, chiropractor etc.. (pay more for electricity and CPU+MOBO and PSU and cooling system) and I anticipate more salary (more credit). That is what David Lenin Anderson misunderstood. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Yep, the same concepts of feedback, slew rates, over-undershoot, and damping/oscillation apply the same. On the cherry-picking, I think it takes all sorts to make the world work, and some would consider that cheating, and others a useful tool. I tend to think it's not that black and white, and that exploits usually point to deeper design flaws. As those flaws affect other things, then they should be fixed for those reasons, and the cherry-pickers can move to look for more flaws ;) Yeah with proper scaling & normalisation, some things become obvious that are not so obvious when buried in noise. Some of that can be exploits (and so design or implementation flaws), and some can be legitimate special situations. The Jackpot situation found here was an unexpected weakness, and something that will have to be examined closely as the system is stabilised. Thanks for the input, I appreciate bouncing the ideas back and forwards a lot. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Holmis Send message Joined: 4 Jan 05 Posts: 104 Credit: 2,104,736 RAC: 0 |
Intel GPU: Another follow up although it's been extensively discussed already. 11 BRP5 Intel GPU tasks has now been validated and the APR has been calculated to 10.78 GFlops running one tasks at a time. The initial estimate was that the iGPU was 53,9 times faster than actual. The peak value reported by Boinc in the startup messages is 13,6 times faster and if that had been used then the tasks would have finished without me having to increase the rsc_fpops_bound value to avoid Boinc aborting the tasks with "maximum time limit exceeded". |
|
nenym Send message Joined: 13 Jun 11 Posts: 14 Credit: 10,001,988 RAC: 0 |
Additional notes. Cherry-pickig. It is very difficult to prevent it selectively, as it can be done not by aborting only, also by killing process via taskmanager. And aborting could be really cherry-picking or: - missed deadlines (could be sorted), - unexpected reasons (HW fault of host...), - end of a challenge (Pentathlon, PG challenge series - PG explicitly asks for aborting unneeded tasks), - overestimated fpops and consequential preventing of a panic mode... Lowering of the daily quota (according to actual formula N=N-n_of_errored_tasks) is not enough for preventing, because it can be simply passed by time-to-time finished work. It is mission impossible by my POW. Regulation process. Reaching the asymptote can be accelerated using granted credit boundaries (independetely on rsc_fpops_est) on a validator side for a sort/batch of WUs if it makes sense. Yes, it is additional work for developers and administrators, could be partially automated using "reference" machine. On the other side - it can be a wrong way theoretically because of two regulation parameters of the same quantity. I feel you did not implicate credit bounds to see design or implementation flaws in raw algorithm. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Additional notes. Yep there are fixed bounds in play, and the 'safeties' are being tripped as new apps come online, actually introducing more problems ( like a car airbag that goes off at the slightest bump, and then has a spike mounted on the steering wheel behind it). Part of the cause of that is gross scaling error for the onramp period. Further looks & fix decisions at where bounds should really be set are needed after gross scaling errors in CPU and GPU are improved. It appears that they may be too tight even with good initial scaling, because of diversity in applications and how people use their machines ... Basically the system seems to assume dedicated crunching to some degree, which is quite a false assumption. Then you have the multiple tasks per GPU situation, which is not factored in anywhere. The reason some of these weaknesses are known is in part that I experienced none of the client side failsafes, because I use a modified client where I widened them. I could see the scales hard-lock to max limits and still give estimates too short. This means the initial server side scale being applied was way out of whack in comparison to the estimate of GPU speed. It turns out one assumption, that GPUs are 10% of their peakflops, is commented in the server code as being 'generous'. In fact even for the common case of 1 GPU task per GPU this is not generous, but results in estimates that are too short, and when combined with the initial app scalings result in estimates divided by ~300-1000x... (common scaling case 0.05x0.05=0.0025 -> 1/400) before considering the multiple task per GPU case. Double application of scales that overlap there is also a problem easily remedied. SO that's how both the initial scalings, stability, and possibly overtight failsafe margins interact, and addressign the first two issues should give a clear indication of where the third should be adjusted into safe limits. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
tullio Send message Joined: 22 Jan 05 Posts: 796 Credit: 137,342 RAC: 0 |
A gamma-ray unit ended with "Elapsed time exceeded". But the estimated time to completion was only 2 hours, compared to 76 hours in Einsten@home. Tullio |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
I've been away over the weekend, and I won't have time to retrieve the data for the 'validation time' graph until much later this evening. But here's the logarithmic scale graph, updated and extended. I think we can see that the 'upper mode' has a distinct, converging, trendline too - but there's still 300-400 credits difference between the upper and lower modes. 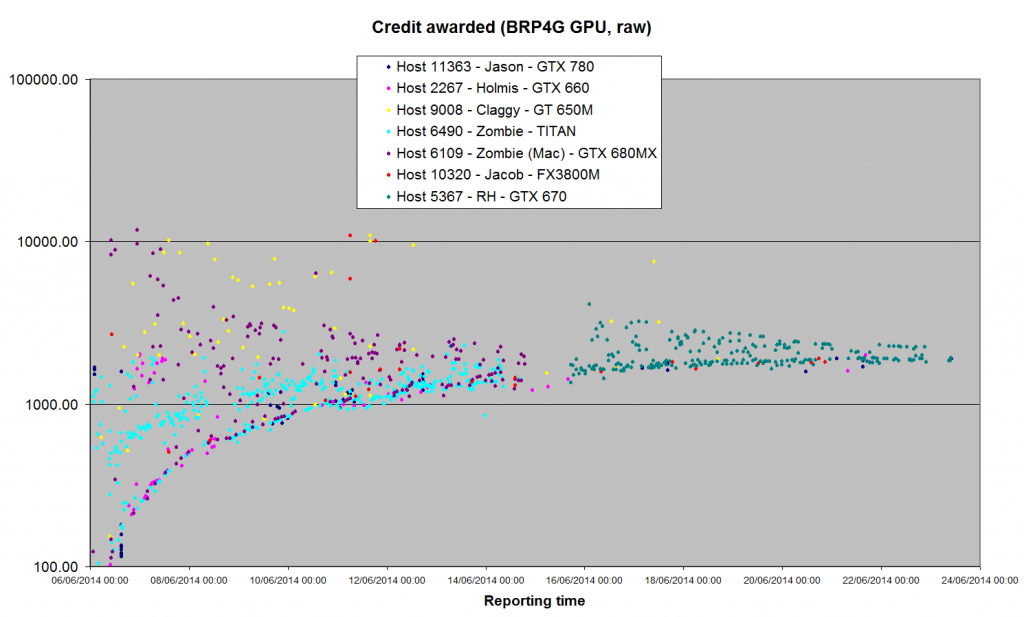 |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Has the median for your results there, restricted to the seoncd half of the month, settled to around 2340 ? If so, then the global (app_version) pfc_scale for the GPU app has settled roughly where expected. That indicates the GPU portion is not normalised againt a CPU version, and that 300-400 variation is likely the remaining host_scale and averaging instabilities. Without the CPU app ~2.25x (down)scaling attractor, I feel the level is reasonable/correct, though (imo) a month far too long to dial in a new app version, from too wide of a start, and that the noise is unnecessary & induced. extra notes & predictions before going forward: In this context (CPU app free, critically *AFTER* app_version scale has converged), the *correct* claim will be the lower of two as David had implemented, and the averaging between the two claims adding noise. With damping of the scales the awards would become a relatively smooth curve. That final wingman average (IIRC Eric added) is critically important elsewhere to mitigate the CPU downscaling error induced underclaim. With that the upward spread is overclaim by the high pfc hosts. Summarising, we should be able to confidently address the coarse scaling errors on both CPU and initial GPU, which will speed new application and new host convergence. We should be able to remove the bulk of the noise and remove the sensitivity to the initial project estimate, which combined will address all of the main concerns people have with the current implementation from user and project perspectives, so once the weather settles a bit here in Oz (and I've cleaned up the royal mess in the yard) time to roll up the sleeves & get patching. At this point I doubt any new major observations will jump out, though I'd like to keep an eye on things while code-digging in the background. Unstable is as unstable does, and things can jump out and surprise us, though since that data appears to characterise all the known issues well, then IMO we have a good baseline to improve on. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Has the median for your results there, restricted to the seoncd half of the month, settled to around 2340 ? If so, then the global (app_version) pfc_scale for the GPU app has settled roughly where expected. That indicates the GPU portion is not normalised againt a CPU version, and that 300-400 variation is likely the remaining host_scale and averaging instabilities. The median for the whole population for host 5367 (nSamples = 250) is 1880.63 (mean 2030.77): if you'd like to give me your formula for "second half of the month" - by reporting or validation date? - I can pull that out, but it doesn't look as if it would be as high as 2340. Here's the current linear graph by validation time. 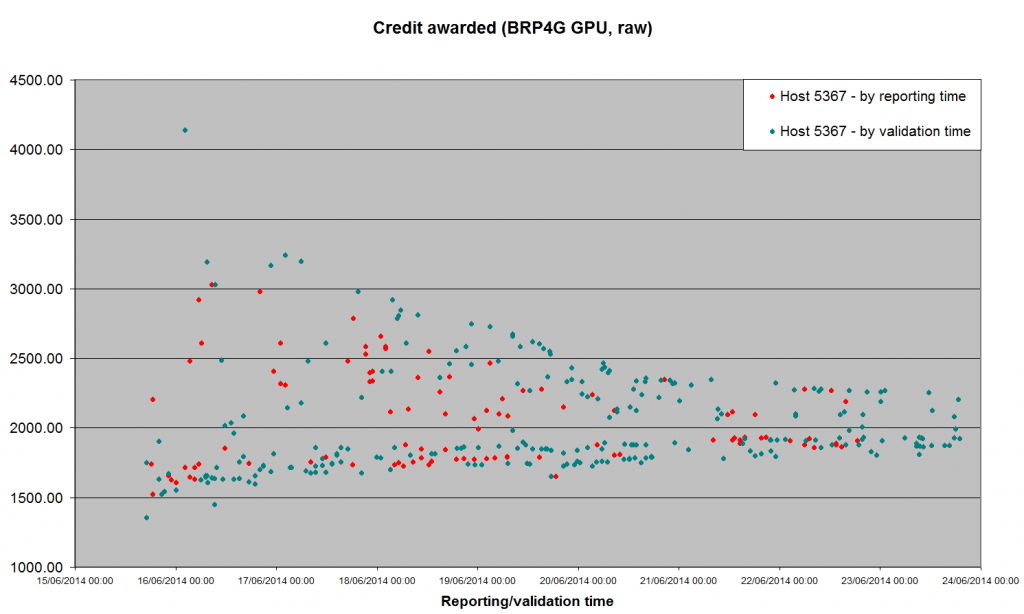 |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
No that's OK Thanks. When you're dealing with control systems it's the intuition that counts, as control is a subjective experience based thing. With what we have We CAN already say there is apparent convergence (after a long time) which is good enough for computers, but not all that crash hot for human perception/intuition. It's quite acceptable for the mechanism to be applying some small offset either way, to cover some little understood phenomena... that's why a cointrol system and not a fixed knob. As we're dealing with human concepts, The keys will be improvement in the convergence and noise, which are the key things that are failing projects and users for this GPU only app example. {Edit:] if we get that 'right', plus the CPU coarse scaling issues, then the projects that cross-normalise should also see stabilisation (intuitive level) On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Richard Haselgrove Send message Joined: 10 Dec 05 Posts: 450 Credit: 5,409,572 RAC: 0 |
Updating both graphs, to show a new effect.   This morning, I was asked to change the running configuration on my host 5367, for an unrelated reason. As a result, the maximum runtime for these tasks went up from 4137.85 seconds to 4591.35 - nearly 11%. The first task back after that - before APR had a chance to respond, obviously - is the high outlier at 2474.34 I think that's further evidence of the kind of instability we need to cure. |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
Yes, local estimates need to be responsive to running conditions. It's unfortunate that the existing mechanism for that was disabled instead of completed/fixed. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Claggy Send message Joined: 29 Dec 06 Posts: 78 Credit: 4,040,969 RAC: 0 |
Seti Beta deployed the Blunkit based Optimised AP v7 yesterday, there the estimates are the other way round, my Ubuntu 12.04 C2D T8100 took ~12 hours on it's first Wu, shame the estimates start at ~228 hours. Claggy |
|
jason_gee Send message Joined: 4 Jun 14 Posts: 109 Credit: 1,043,639 RAC: 0 |
LoL, do the results mix with traditional non-blankit versions ? That's going to mess with cross app normalisation bigtime. On two occasions I have been asked, "Pray, Mr. Babbage, if you put into the machine wrong figures, will the right answers come out?" ... I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. - C Babbage |
|
Claggy Send message Joined: 29 Dec 06 Posts: 78 Credit: 4,040,969 RAC: 0 |
AP v6 should only mix with AP v6, and AP v7 should only mix with AP v7. Even better, the SSE2 app is Optimised, the SSE app in non-Optimised, the difference in runtimes is going to be huge, I see carnage ahead. Claggy |
|
Eyrie Send message Joined: 20 Feb 14 Posts: 47 Credit: 2,410 RAC: 0 |
IOW credit for AP should drop. That's one way to get a bit more of cross app balance ;D Queen of Aliasses, wielder of the SETI rolling pin, Mistress of the red shoes, Guardian of the orange tree, Slayer of very small dragons. |
This material is based upon work supported by the National Science Foundation (NSF) under Grant PHY-0555655 and by the Max Planck Gesellschaft (MPG). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the investigators and do not necessarily reflect the views of the NSF or the MPG.
Copyright © 2024 Bruce Allen for the LIGO Scientific Collaboration